

Content operations in a wider digital environment

What happens when you start working in an area that has no real name to it? When it involves content and data, but it’s not “content strategy” exactly, and it’s not “content operations” exactly, and it’s certainly not “data operations”? You adopt a label that is the closest term to what you want to describe. In this case, I coined the term “information operations” or InfoOps.
Since the original post, some five years ago, the industry has undergone massive changes. Generative AI has had particular impact in the content industry. The disruption has been profound. The complexity of operational efficiencies have multiplied, making the techniques of the previous decade look like child’s play in comparison.
What and why of information operations
Most of what we do as practitioners is in response to a business problem, or perhaps a business aspiration. In the case of information operations, it is often a double-barrelled approach to achieving a particular outcome. These outcomes can be stated in several ways; not every organisation may choose to go down the same path.
Some ways of expressing the what and why:
We want to get information out there faster, so we need to automate aspects of content production.
Our data is changing more often than ever, and the team managing the data (sometimes still in spreadsheets) can’t keep up with the multitude of places that the data has to be kept current.
We need to commoditise corporate knowledge – perhaps with real-time publication – so that we have less of a bottleneck in our call centres, providing market-appropriate, personalised information to call centre agents.
We don’t have enough resources to handle all the manual production steps, so we want to build more efficiencly into production.
We want to deliver a personalised customer experience, which means creating more specific content, marrying it with specific data, and delivering it to the right audience segment at the right time.
We want to stop entering data points into our content manually when we know there’s a way to automate that function.
We want to democratise our knowledge by making it available across our client base on a self-serve basis.
The common themes here are efficiency on the creation side, and automation on the delivery side.
For some organisations, the impetus may be to provide a better user experience. For other organisations, the impetus may be to control internal costs. Either way, success depends on the working on both sides, and meeting in the middle.
Building on the DIWK framework of knowledge management
Looking at a traditional knowledge management pyramid, the base is data, building up to information, and resulting in knowledge and wisdom. While this is a useful model within knowledge management to understand the cognitive transformation of raw material (data) into meaningful conclusions, the model needs to be updated to be helpful in explaining the mechanics of delivering information.
To understand the operational side of DWIK, we need to stand the pyramid on its head. First of all, content is a missing element from the entire equation. It may be co-opted into the category of data, but content is inherently different than data and needs its own category. And secondly, in information operations, we cannot strive to create wisdom. Information can be combined and delivered in ways that create a form of knowledge; it’s up to the consumer of that information to contextualise their findings into something more.
The information operations pyramid
The word “operations” is the key to the interpretation of the practice. The explanation of information operations is firmly rooted in the production and delivery sides of the equation, as an operational model that leads to a range of potential outcomes that are varied as the organisations that incorporate the practice.
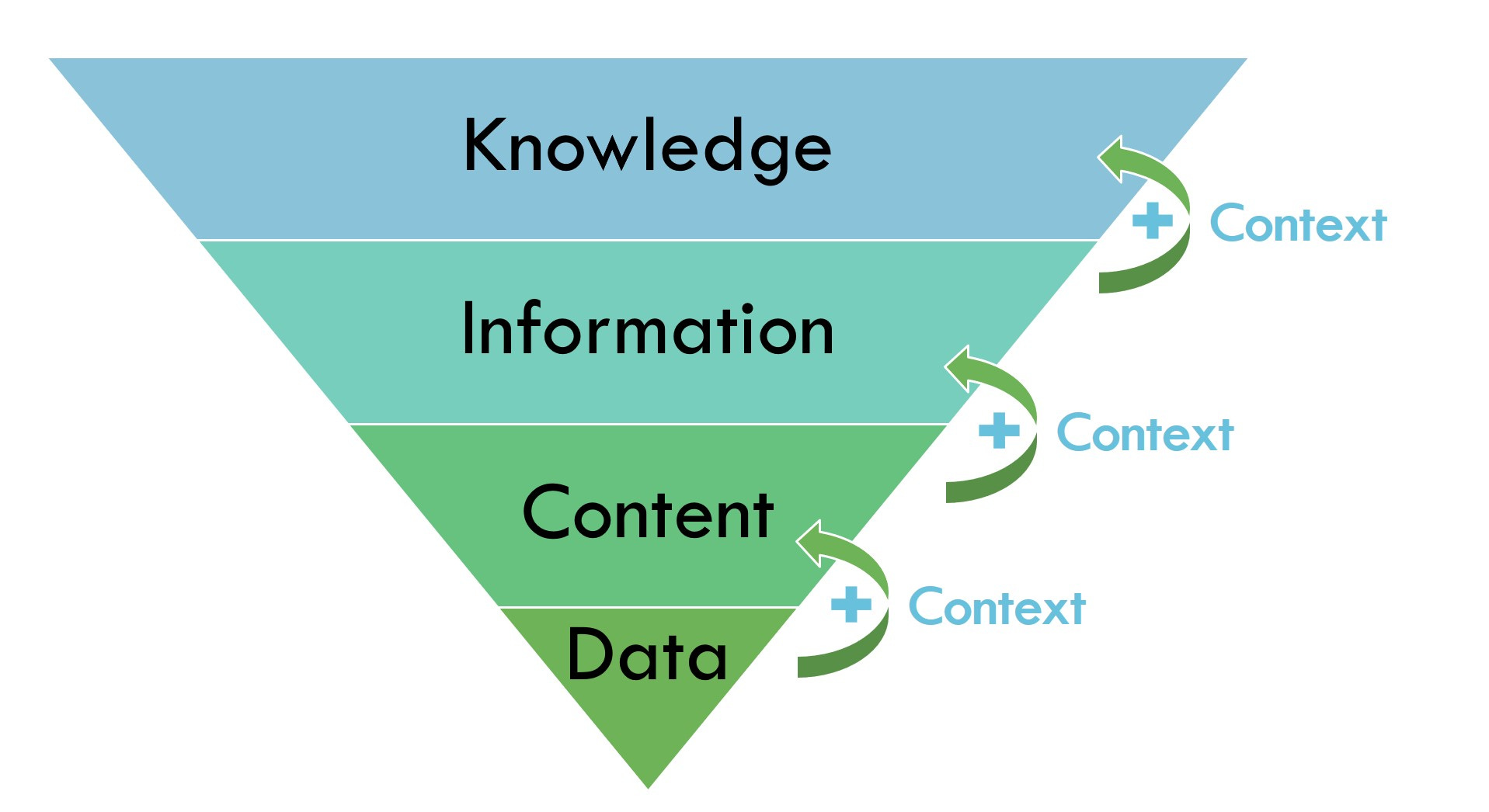
Let’s look at each layer of the inverted pyramid separately.
Data. For InfoOps to work, data needs to operationalised. For purposes of explaining the need behind information operations, the data sets must be maintained in a usable state to be available on demand, to enable dynamic delivery of data. The data can be used to create analyses, data visualisations, or simply to populate data points within content objects. An simple example is “Our company was founded in [year] and has [number] employees. Revenues have grown at a steady rate over the past [number] of years [trend over time graph].” Those data points can be dynamically updated on an ongoing basis, with no intervention from the content developer. There is a lot more to data operations that indirectly benefit information operations, which you can have explained by people much closer to data than me.
Data operationsContent. For InfoOps to work, content needs to be operationalised. Operationalising content is very different from operationalising data. What differentiates content from data is context. Content is human-usable, contextualised data. My usual example is to tell me whether the data point “12” is good or bad. You don’t have enough context to make an informed decision. If it’s a £12 pencil, it’s probably not a good investment; if it’s £12 for a case of pencils, you’re probably getting a better deal. If 12 is a dozen, then you might think eggs, while a baker’s dozen is actually 13. If I tell you that 12 = month, then generally, 12 equals December. There are some explanations about content operations freely available, including this one.
Content OperationsInformation. If content is contextualised data, then you can consider information to be contextualised content. Unfortunately the term “information operations” seems to have been adopted in the USA to mean “support for military operations”. Outside of that very specific definition, operationalising information can take many forms. Here are two examples.
In the first example, we look at embedding data parameters into a piece of content, as follows. “How many countries are in the world? The UN recognises [number] countries and territories. The USA officially recognizes fewer than [number] nations. Ultimately, the most recognised answer is that there are [number] countries in the world.” The numbers on their own would be meaningless without the context provided by the text surrounding them. Automating the insertion of data into the content in real time allows us to update the data points from time to time without intervention by the writer.
In the second example, the data does the heavy lifting. An investment app I use shows me an image with a dynamically-generated, up-to-the-minute analysis of a financial investment, supplemented by enough content to explain what the chart means. This is to allow users to understand the ROI they are getting on their investments. The data is most important, with content playing a supporting role.
You can read about commoditising information in a few places, though one of the most accessible articles I found insists on calling content “data” all the way through it.
Commoditisation of Information
Output of information operations
Information is the input; knowledge is the outcome. It is fitting that knowledge is at the top of my InfoOps pyramid, as the combined outcome of a number of content and data inputs can result in many different combination of results. In the earlier example of 12 = December, a European resident may conclude that it might be a nice time to travel in Thailand, whereas Thai business owners may conclude that they need to know how to brave an onslaught of European tourists or stock up on merchandise for their souvenir shops.
When it comes to enhancing a user experience with that information, some of the process can be automated – recommendation engines deliver different information to different audiences all the time, sometimes with hilariously inappropriate results – and other aspects require the recipient to consider their own contexts. We can provide information, but the rest is up to the information consumers to draw their own conclusions, and make knowledge out of the information.
Benefitting from information operations
Striving for operational efficiencies has increased in complexity of execution. The addition of AI into the mix has introduced great opportunity - but also with the corollary risk and responsibility. In the vein of “it takes a village”, in this case, it takes a content ecosystem to make your information operations happen. And that means developing a strong strategy, in conjunction with the data, knowledge management, and AI teams to implement that strategy that works within the larger ecosystem.
================
If your organisation is interested in what benefits a strong operational strategy can bring to your processes, feel free to get in touch.